Volunteers
| Name | ML Category |
|---|---|
| Jahanvi | Supervised |
| Akanksha | Unsupervised |
| Kanak Raj | Reinforced |
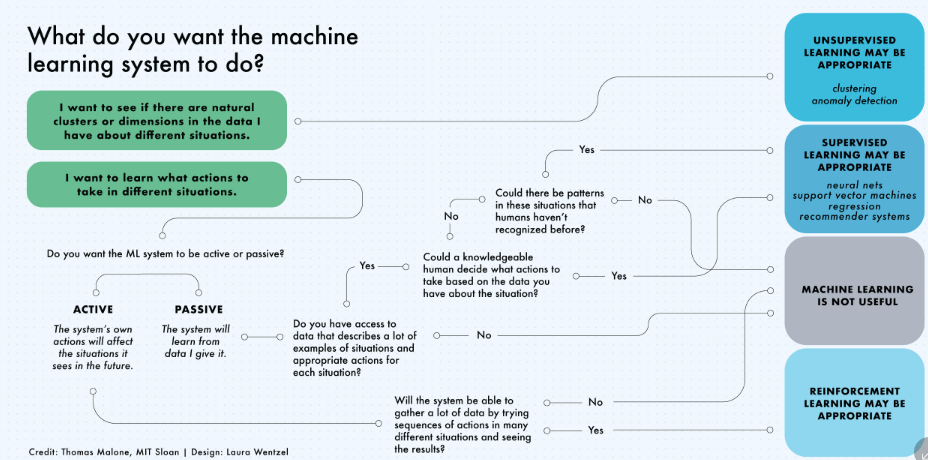
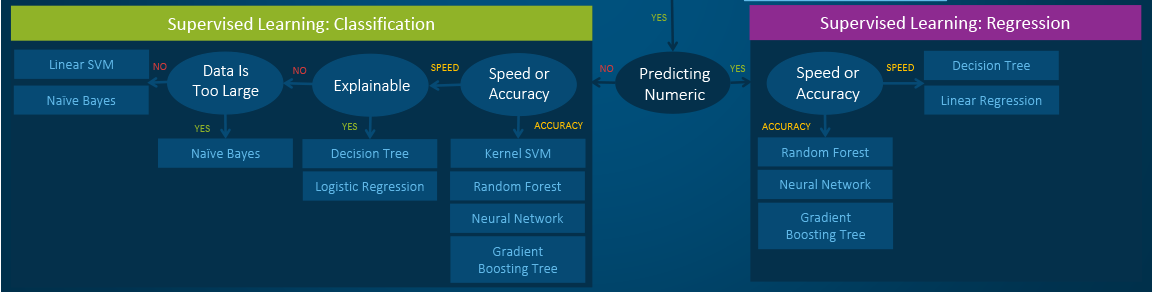
Supervised
- Supervised learning algorithms make predictions based on a set of examples
- Classification: When the data are being used to predict a categorical variable, supervised learning is also called classification. This is the case when assigning a label or indicator, either dog or cat to an image. When there are only two labels, this is called binary classification. When there are more than two categories, the problems are called multi-class classification.
- Regression: When predicting continuous values, the problems become a regression problem.
- Forecasting: This is the process of making predictions about the future based on past and present data. It is most commonly used to analyze trends. A common example might be an estimation of the next year sales based on the sales of the current year and previous years.
Algorithms
In progress**
| Name | Comments on Applicability | Reference |
|---|---|---|
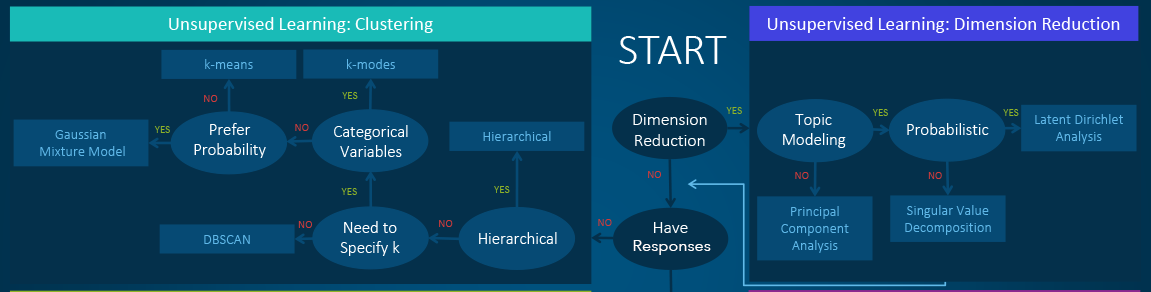
Un-supervised
- Clustering - hierarchical clustering, k-means, mixture models, DBSCAN, and OPTICS algorithm
- Anomaly Detection - Local Outlier Factor, and Isolation Forest
- Dimensionality Reduction - Principal component analysis, Independent component analysis, Non-negative matrix factorization, Singular value decomposition
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
| Hierarchical Clustering |
| |
| k-means |
| |
| Gaussian Mixture Models |
Reinforcement Learning
- Active Learning
- No labeled data
- No supervisor, only reward
- Actions are sequential
- Feedback is delayed, not instantaneous.
- Can afford to make mistakes?
- Is it possible to use a simulated environment for the task?
- Lots of time
- Think about the variables that can define the state of the environment.
- State Variables and Quantify them
- The agent has access to these variables at every time step
- Concrete Reward Function and Compute Reward after action
- Define Policy Function
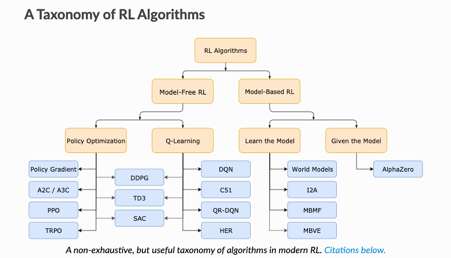
Model-Free vs Model-Based RL
Whether the agent has access to (or learns) a model of the environment(a function that predicts state transitions and rewards)
Model Free | Model-Based |
forego the potential gains in sample efficiency from using a model | Allows to plan ahead and look in possible results for a range of possible choices. |
easier to implement and tune. | Ground Truth Model for any task is generally not available. |
If agents want to use a model then it has to prepare it purely from experience | |
fundamentally hard | |
being willing to throw lots of time | |
High computation | |
Can fail off due to over-exploitation of bias |
What to Learn in Model-Free RL
- Policy Optimization
Q-Learning
Policy Optimization
Q-Learning
optimize the parameters either directly by gradient ascent on the performance objective or indirectly, by maximizing local approximations
learn an approximator for the optimal action-value function
performed on-policy, each update only uses data collected while acting according to the most recent version of the policy
performed off-policy, each update can use data collected at any point during training
directly optimize for the thing you want
indirectly optimize for agent performance
More stable
tends to be less stable
advantage of being substantially more sample efficient when they do work, because they can reuse data more effectively
Less sample efficient and takes longer to learn as learning data is limited at every iteration.
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
Q Learning | ||