Volunteers
| Name | ML Category |
|---|---|
| Jahanvi | Supervised |
| Akanksha | Unsupervised |
| Kanak Raj | Reinforced |
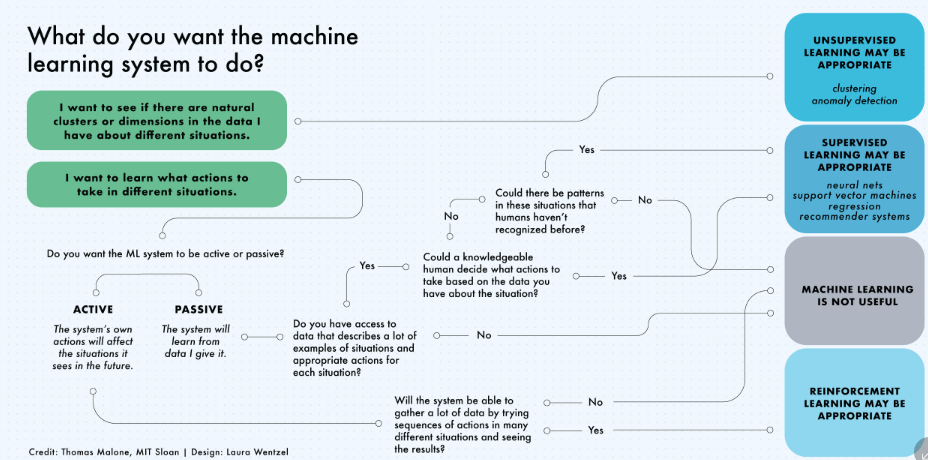
Supervised
- Supervised learning algorithms make predictions based on a set of examples
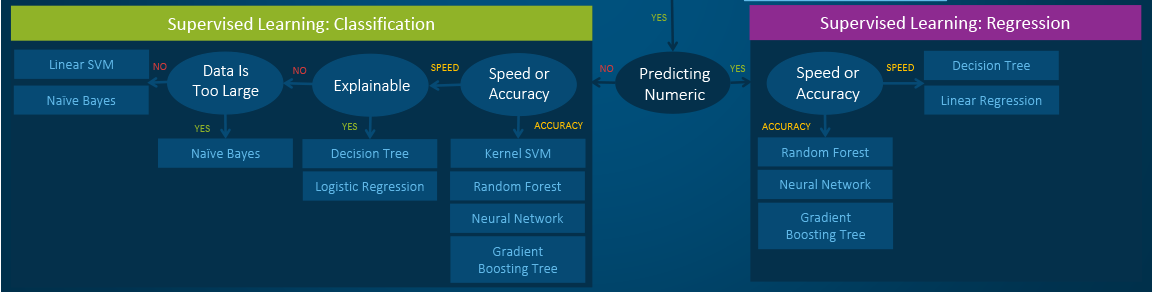
- Classification: When the data are being used to predict a categorical variable, supervised learning is also called classification. This is the case when assigning a label or indicator, either dog or cat to an image. When there are only two labels, this is called binary classification. When there are more than two categories, the problems are called multi-class classification.
- Regression: When predicting continuous values, the problems become a regression problem.
- Forecasting: This is the process of making predictions based on past and present data. It is most commonly used to analyze trends. A common example might be an estimation of the next year sales based on the sales of the current year and previous years.
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
| LOGISTIC REGRESSION |
| |
KNN |
| |
| SUPPORT VECTOR MACHINE |
| |
| Kernel SVM |
| |
| RBF Kernel |
So, the rule thumb is: use linear SVMs for linear problems, and nonlinear kernels such as the RBF kernel for non-linear problems. | |
| NAIVE BAYES |
| |
| DECISION TREE CLASSIFICATION |
| |
| RANDOM FOREST CLASSIFICATION |
| |
| GRADIENT BOOSTING CLASSIFICATION |
|
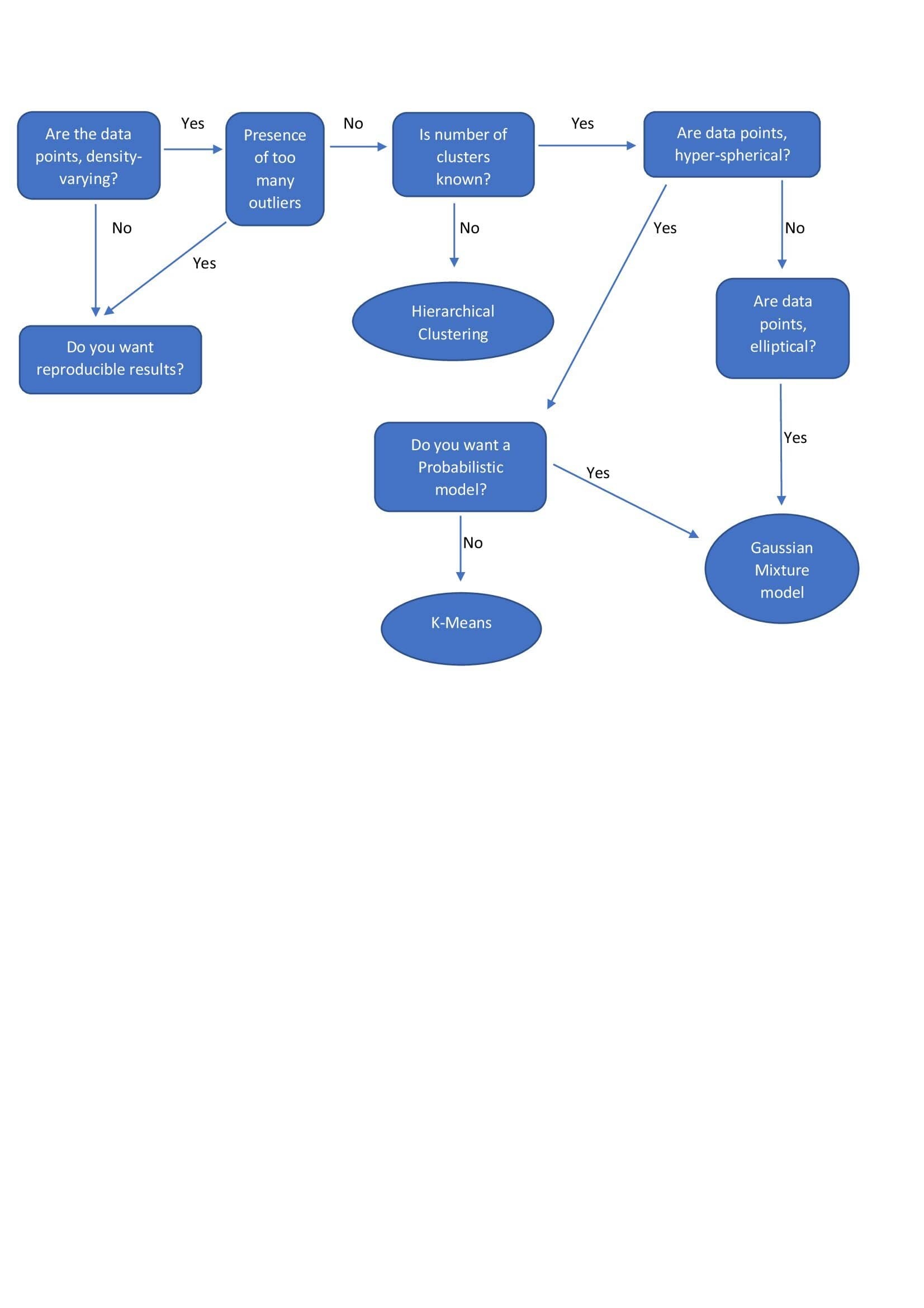
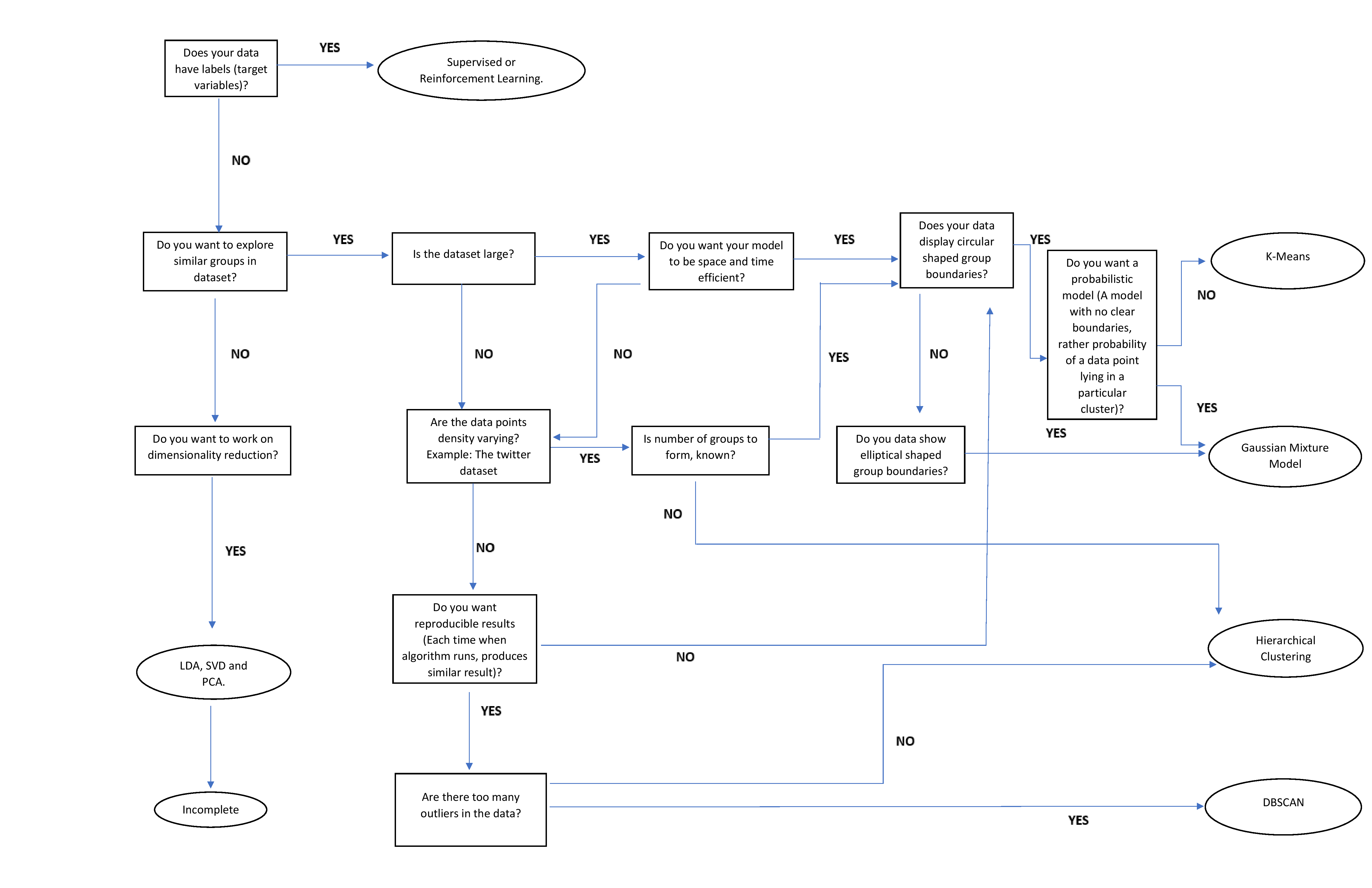
Un-supervised
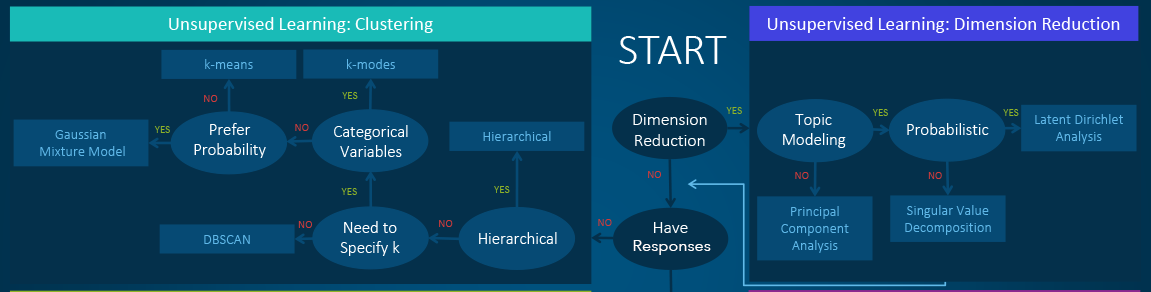
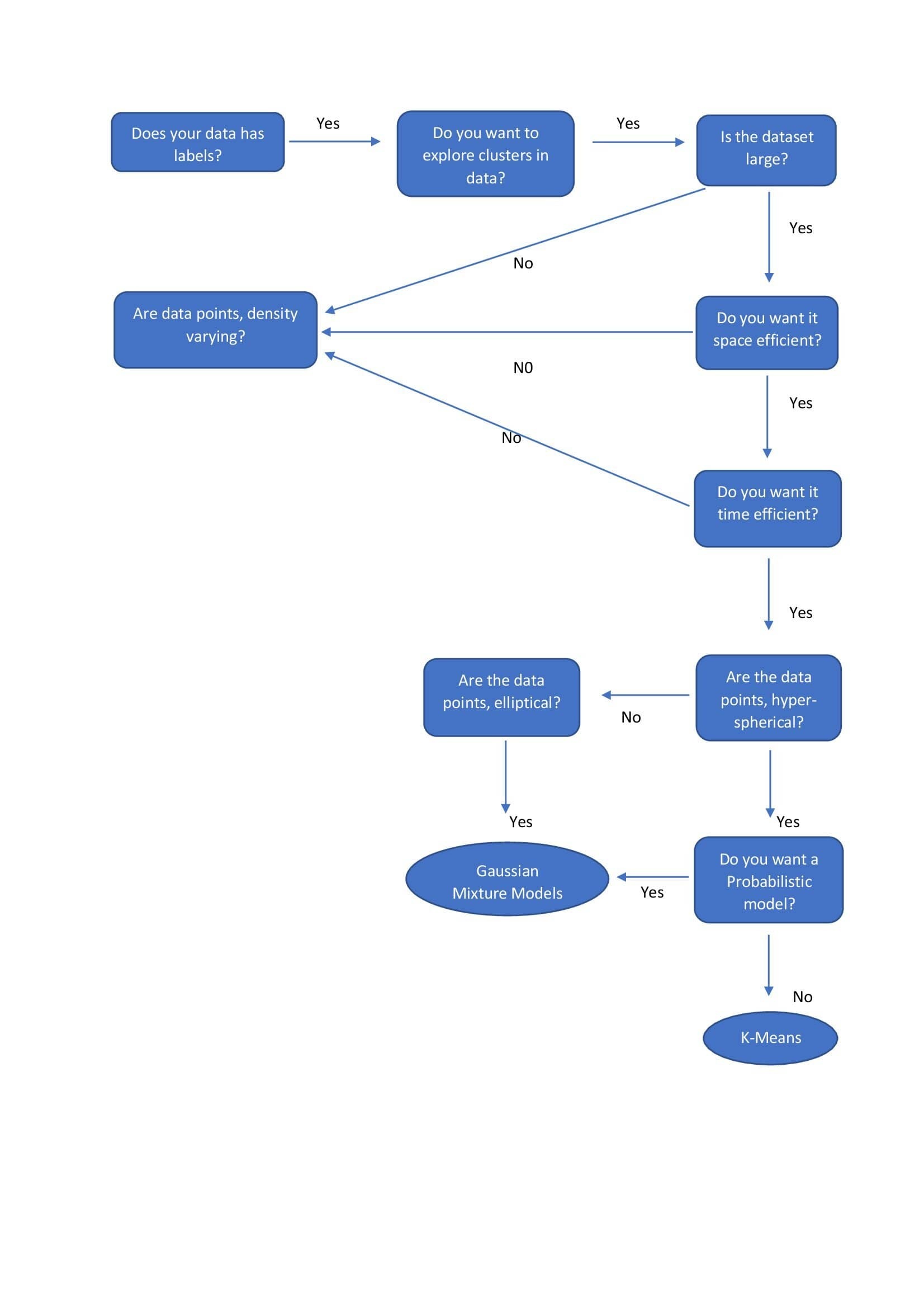
- Clustering - hierarchical clustering, k-means, mixture models, DBSCAN, and OPTICS algorithm
- Anomaly Detection - Local Outlier Factor, and Isolation Forest
- Dimensionality Reduction - Principal component analysis, Independent component analysis, Non-negative matrix factorization, Singular value decomposition
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
| Hierarchical Clustering |
| |
| k-means |
| |
| Gaussian Mixture Models |
| |
| DBSCAN |
|
| DIMENSIONALITY REDUCTION ALGORITHMS | APPLICABILITY |
|---|---|
| Linear Discriminant Analysis | It is used to find a linear combination of features that characterizes or separates two or more classes of objects or events. LDA is a supervised LDA is also used for clustering sometimes. And almost always outperforms logistic regression. |
| Principle Component Analysis | It performs a linear mapping of the data from a higher-dimensional space to a lower-dimensional space in such a manner that the variance of the data in the low-dimensional representation is maximized. PCA is unsupervised |
Reinforcement Learning
- Active Learning
- No labeled data
- No supervisor, only reward
- Actions are sequential
- Feedback is delayed, not instantaneous.
- Can afford to make mistakes?
- Is it possible to use a simulated environment for the task?
- Lots of time
- Think about the variables that can define the state of the environment.
- State Variables and Quantify them
- The agent has access to these variables at every time step
- Concrete Reward Function and Compute Reward after action
- Define Policy Function
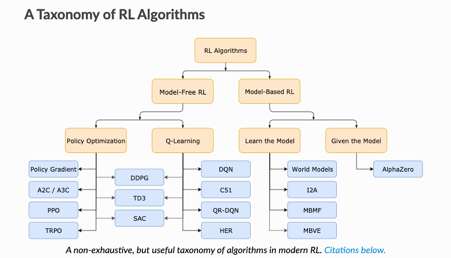
Model-Free vs Model-Based RL
Whether the agent has access to (or learns) a model of the environment(a function that predicts state transitions and rewards)
Model Free | Model-Based |
forego the potential gains in sample efficiency from using a model | Allows to plan ahead and look in possible results for a range of possible choices. |
easier to implement and tune. | Ground Truth Model for any task is generally not available. |
If agents want to use a model then it has to prepare it purely from experience | |
fundamentally hard | |
being willing to throw lots of time | |
High computation | |
Can fail off due to over-exploitation of bias |
When would model-free learners be appropriate?
If you don't have an accurate model provided as part of the problem definition, then model-free approaches are often superior.
Model-based agents that learn their own models for planning have a problem that inaccuracy in these models can cause instability (the inaccuracies multiply the further into the future the agent looks).
If you have a real-world problem in an environment without an explicit known model at the start, then the safest bet is to use a model-free approach such as DQN or A3C.
The distinction between model-free and model-based reinforcement learning algorithms is analogous to habitual and goal-directed control of learned behavioral patterns. Habits are automatic. They are behavior patterns triggered by appropriate stimuli (think: reflexes). Whereas goal-directed behavior is controlled by knowledge of the value of goals and the relationship between actions and their consequences.
What's the difference between model-free and model-based reinforcement learning?
RL problem is formulated as Markov Decision Process.
Represents the dynamics of the environment, the way the environment will react to the possible actions the agent might take, at any given state.
Transition Function: Fn(state, action) → P(all next possible states)
Reward Function: Fn(state) → Reward
The Transition Function and Reward Function constitutes the "model" of the RL problem.
Therefore, MDP is the problem and Policy Function is its solution.
The model-based RL can be of two types, algorithm learn the model separately or model is provided.
Examples of Model: Rules of Games, Rules of Physics, etc.
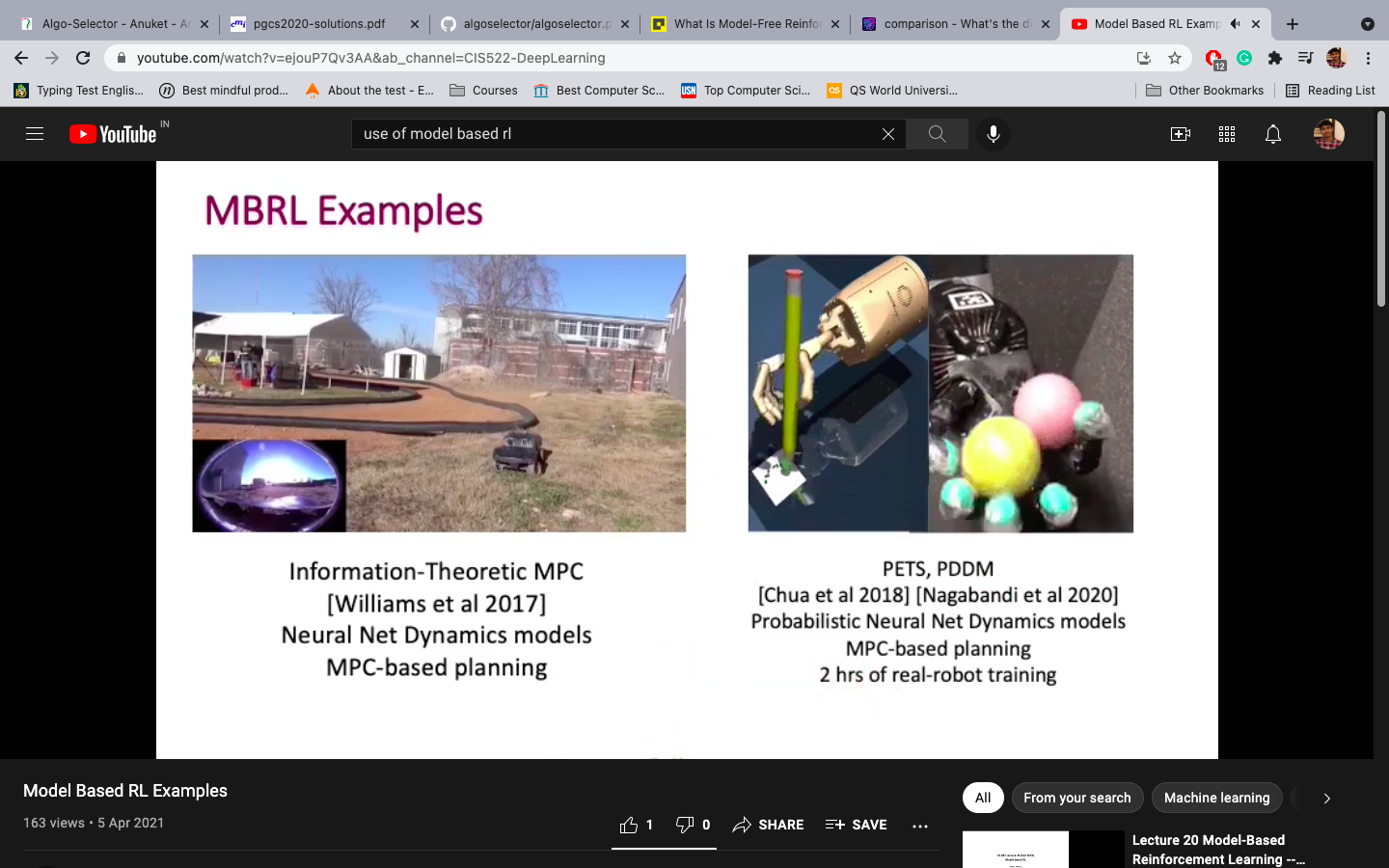
In the Absence of MDP, Agent Interacts with the environment and observes the responses of the environment. They don't have any transition or reward function, the algorithms purely sample and learn from the experience. They rely on real samples from the environment and never use generated predictions of the next state and next reward to alter behavior.
A model-free algorithm either estimates a "value function" or the "policy" directly from experience. A value function can be thought of as a function that evaluates a state (or an action taken in a state), for all states. From this value function, a policy can then be derived.
Examples: Robot Hand Trying to Solve Rubix Cube, Robotic Model learn to walk, etc. These tasks can be learned in a "model-free" approach.
There is no direct distinction b/w model-free and model-based by applications. The use of the algorithm depends upon if "model" is provided or can be learned then use "model-based" else use "model-free".
What to Learn in Model-Free RL
- Policy Optimization
Q-Learning
Policy Optimization
Q-Learning
optimize the parameters either directly by gradient ascent on the performance objective or indirectly, by maximizing local approximations
learn an approximator for the optimal action-value function
performed on-policy, each update only uses data collected while acting according to the most recent version of the policy
performed off-policy, each update can use data collected at any point during training
directly optimize for the thing you want
indirectly optimize for agent performance
More stable
tends to be less stable
advantage of being substantially more sample efficient when they do work, because they can reuse data more effectively
Less sample efficient and takes longer to learn as learning data is limited at every iteration.
- Value-based methods
- (Q-learning, Deep Q-learning): where we learn a value function that will map each state action pair to a value.
- find the best action to take for each state — the action with the biggest value.
- works well when you have a finite set of actions.
- Policy-based methods
- REINFORCE with Policy Gradients
- we directly optimize the policy without using a value function.
- when the action space is continuous or stochastic.
- use total rewards of the episode
- problem is finding a good score function to compute how good a policy is
- Hybrid Method
- Actor-Critic Method
- Policy Learning + Value Learning
- Policy Function → Actor: Choses to make moves
- Value Function → Critic: Decides how the agent is performing
- we make an update at each step (TD Learning)
- Because we do an update at each time step, we can’t use the total rewards R(t).
- Both learn in parallel, like GANs
- Not Stable but several variations which are stable
- Actor-Critic Method
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
Q Learning | ||
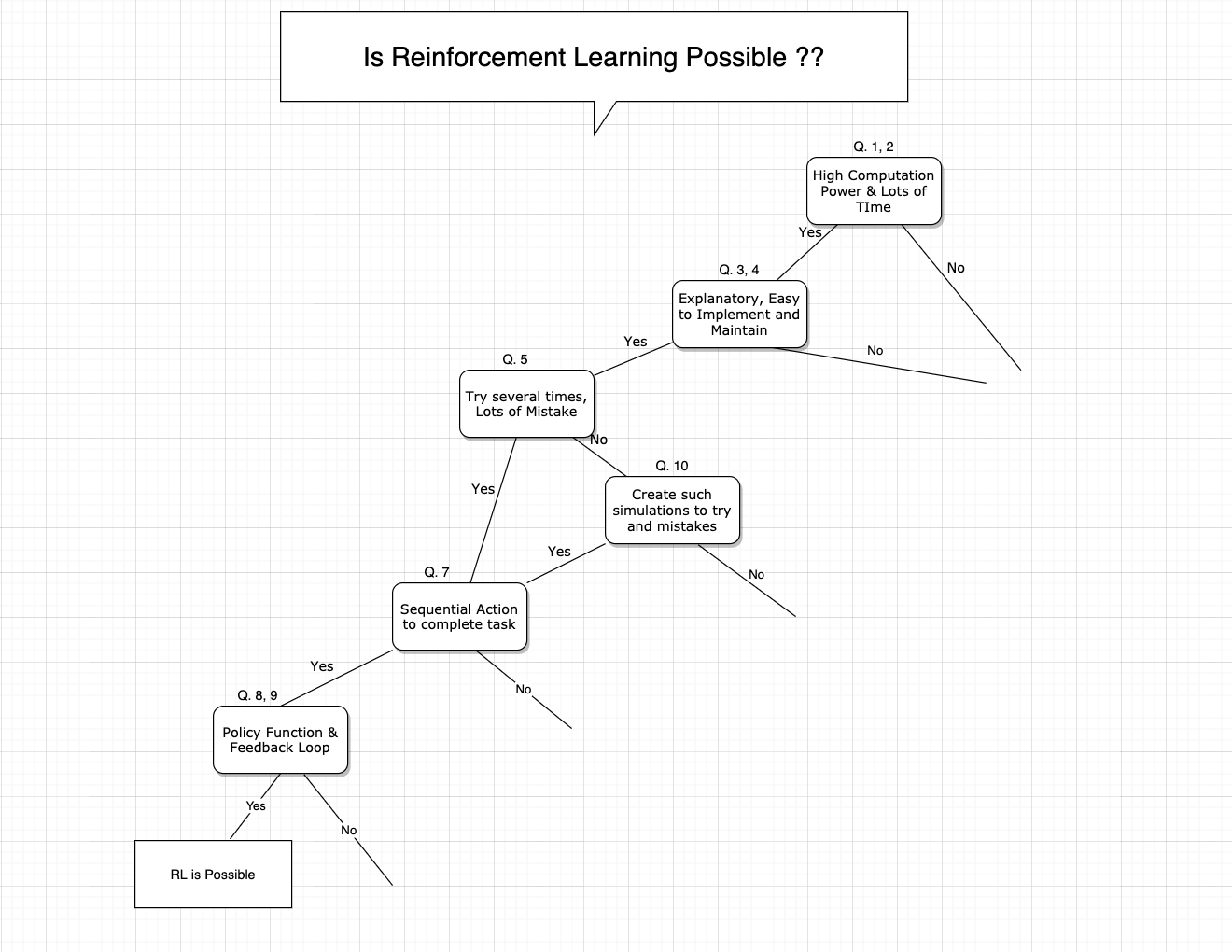
Is RL Possible?
- Do you have very high computation power?
- Do you have lots of time to train an agent?
- Do you need your model to be self-explanatory, humans can understand the reasoning behind the predictions and decisions made by the model?
- Do you need your model to be easy to implement and maintain?
- Is it possible to try the problem several times and afford to make many mistakes?
- In your situation, do active and online learning of algorithms is possible i.e while learning by actions, explore new data space and then learn from such conditions and data?
- In your situation, Can the algorithm take sequential action and complete the task?
- Is it possible to define policy function, actions that the agent takes as a function of the agent's state and the environment.?
- Is it possible to define a function to receive feedback from actions, such that feedback helps to learn and take new action?
- Can you simulate an environment for the task so that algorithm can try lots of times and can make mistakes to learn?
Model-Based vs Model Free :
Do you have a probability function that helps you to select new actions based on current action?
If a model is not available, Is it possible to train such a model?