...
| Name | Comments on Applicability | Reference |
|---|---|---|
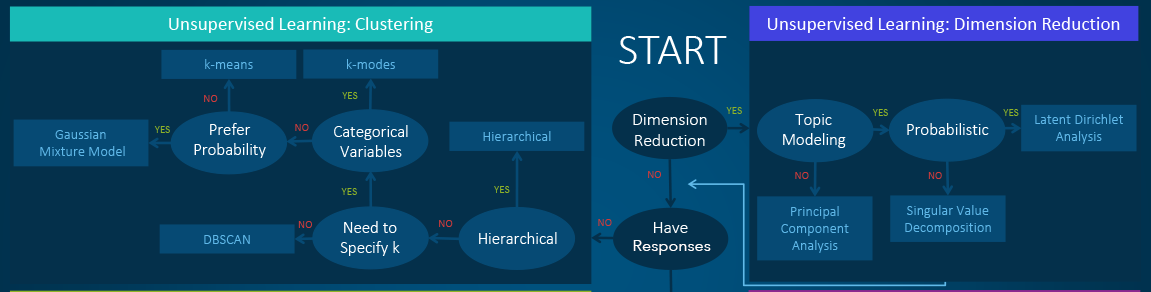
Un-supervised
- Clustering - hierarchical clustering, k-means, mixture models, DBSCAN, and OPTICS algorithm
- Anomaly Detection - Local Outlier Factor, and Isolation Forest
- Dimensionality Reduction - Principal component analysis, Independent component analysis, Non-negative matrix factorization, Singular value decomposition
Algorithms
| Name | Comments on Applicability | Reference |
|---|---|---|
| Hierarchical Clustering |
| |
| k-means |
| |
| Gaussian Mixture Models |
...