Old implementation
With the old collectd VES plugin implementation, the VES plugin:
- Received telemetry directly from collectd.
- Formatted a VES event with the received stats.
- Submitted the stats directly to the VES collector
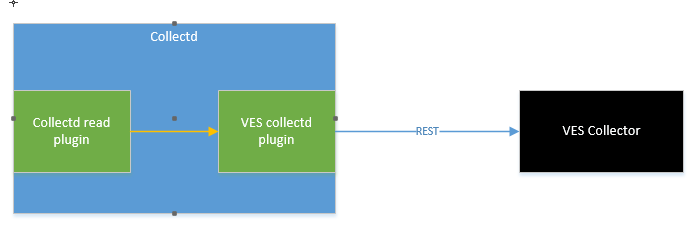
However this model forced an MIT license on the VES collectd plugin when we really needed it to be Apache v2 based. Also, everytime there was a VES schema update we had to make code changes to support the new schema.
Updated implementation
The updated implementation to the collectd involves the following:
- Separation of the VES plugin to a separate application so that it can be licensed appropriately.
- Using a kafka messaging bus to transfer stats from collectd to the new application.
- Using a YAML file to configure the mapping from collectd stats to VES events.
Kafka Integration
The following section is from a readout from volodymyrx.mytnyk@intel.com on Kafka
Kafka Overview
"Apache Kafka is a distributed commit log service that functions much like a publish/subscribe messaging system, but with better throughput, built-in partitioning, replication, and fault tolerance. Increasingly popular for log collection and stream processing" 0
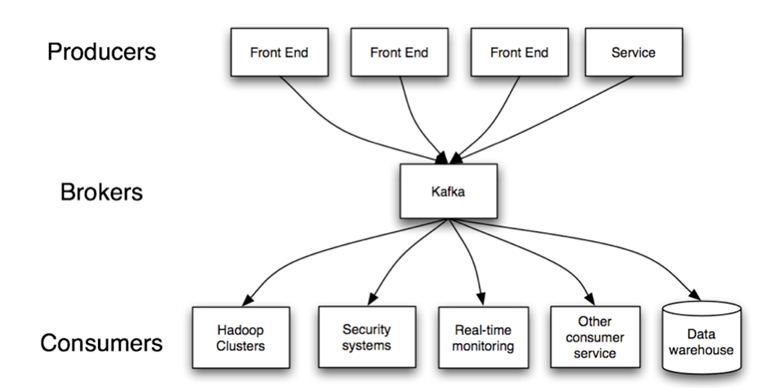
- "Producers – consume the data feed and send it to Kafka for distribution to consumers". 1
- "Consumers – applications that subscribe to topics; for example, a custom application or any of the products listed at the bottom of this post". 1
- "Brokers – workers that take data from the producers and send it to the consumers. They handle replication as well". 1
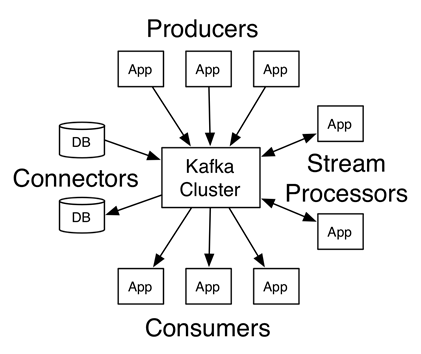
Kafka Use Cases
Topics and partitions
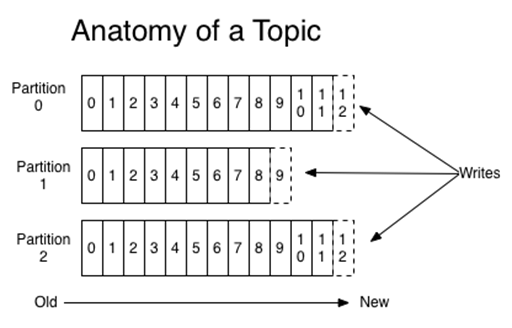
"Partitions – the physical divisions of a topic, as shown in the graphic below. They are used for redundancy as partitions are spread over different storage servers" 1.
"Topics – categories for messages. They could be something like “apachelogs” or “clickstream”". 1
Kafka Features
- Guaranties ordering within the partition.
- Stores all the records as a commit log (for configured interval time, etc.).
- Support partition replication (fault tolerance).
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent.
- A consumer instance sees records in the order they are stored in the log.
- A consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
- Balance messages between consumers in the group.
- There is NO message prioritization support.
Consumer groups

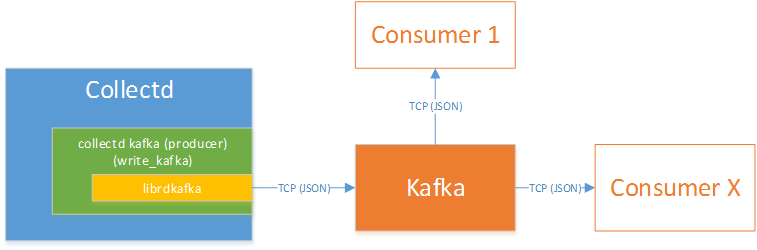
Kafka - collectd
Producer throughput:
50 million small (100 byte) records as quickly as possible.
Test Case | Measurement |
1 producer thread, no replication | 821,557 records/sec (78.3 MB/sec) |
1 producer thread, 3 asynchronous replication | 786,980 records/sec (75.1 MB/sec) |
1 producer thread, 3 synchronous replication | 421,823 records/sec (40.2 MB/sec) |
3 producers, 3 async replication | 2,024,032 records/sec (193.0 MB/sec) |
Consumer throughput
Consume 50 million messages.
Test Case | Measurement |
Single Consumer | 940,521 records/sec (89.7 MB/sec) |
3x Consumers | 2,615,968 records/sec (249.5 MB/sec) |
End-to-end Latency | ~2 ms (median) |
References:
0 https://www.cloudera.com/documentation/kafka/1-2-x/topics/kafka.html
1 https://anturis.com/blog/apache-kafka-an-essential-overview/
- Documentation (http://kafka.apache.org/documentation.html)
- Benchmarking Apache Kafka (https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines)
- Robust high performance C/C++ library with full protocol support (https://github.com/edenhill/librdkafka)