Data
| Failure Type | Failure parameter |
|
| Comments | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Links | Link Down. Link removed | Virtual Switch link failure Reason: Hardware Failure Interface Down
(Ref: https://docs.openstack.org/ocata/config-reference/networking/logs.html) | Network interface status, High packet drop, low throughput, excessive latency or jitter crc-statistics, fabric-link-failure, link-flap, transceiver-power-low | |||||||||||||||||||||||||||||||
| VM | Deployment/Start Failures:
Post-Deployment/Start failures:
| nova-compute.log nova-api.log nova-scheduler.log libvirt.log qemu/$vm.log neutron-server.log glance/cinder - flavor Node and Core-mapping | cpu: per-core utilization memory Interfaces statistics - sent, recv, drops Disk Read/Write | If possible, Infrastructure metrics and syslogs from within the VM should be collected. Deployment/Start failures can be the first step. | ||||||||||||||||||||||||||||||
| Container | Deployment/Start Failures:
Post-Deployment/Start failures:
|
| cpu: per-core utilization memory Interfaces statistics - sent, recv, drops Disk Read/Write | |||||||||||||||||||||||||||||||
| Node | A node failure (hardware failure, OS crash, etc) A) node network connectivity failure B) nova service failure C) Failure of other OpenStack services | /var/log/nova/nova-compute.log
(Ref: https://docs.openstack.org/operations-guide/ops-logging.html) A) node network connectivity failure
B) nova service failure (e.g., process crashed) -- detected and restarted by a local watchdog process
C) Failure of other OpenStack services -- N/A, assuming redundant/highly available configuration
| Interfaces statistics - sent, recv, drops Hypervisor Metrics, Nova Server Metrics, Tenant Metrics, Message Queue Metrics Keystone and Glance Metrics | |||||||||||||||||||||||||||||||
| Application | Crash/Connectivity/Non-Functional | Application Log i.e. If it is Apache then logs of Apache | Packet Drops, Latency, Throughput, Saturation, Resource Usage | Deploy Collectd within the application and collect both application logs and infrastructure metrics | ||||||||||||||||||||||||||||||
| Middleware Services |
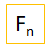
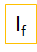
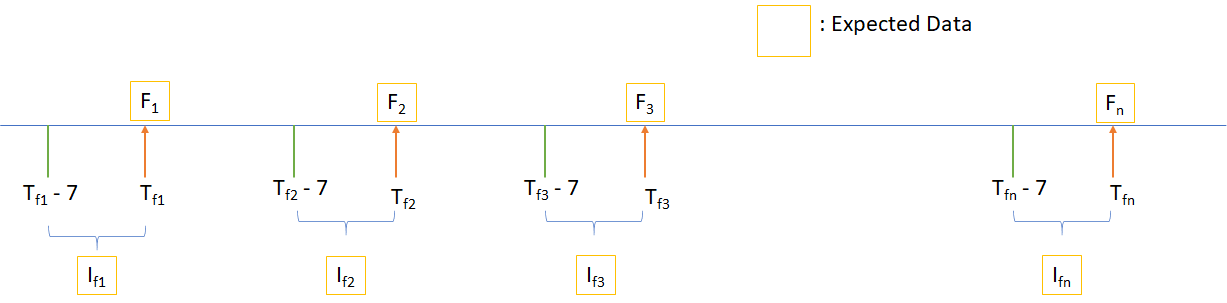
Models
We have taken three types of models and in those models we have considered Failure Prediction problem and the remaining types are given as:
- Event Correlation
- Anomaly Detection
- Failure Prediction
We are focusing on Failure Prediction of Node, Application, VM, Service, Container and Links. Our aim is to predict the failures before they happen so that user can take necessary actions regarding those failures. So, to implement Failure Prediction models we are developing our models using Classical Neural Networks techniques i.e. RNN & LSTM.
Gaps
From the perspective of Telco after doing a literature survey we found most of the work has done on VM and Applications. There are less work has done for Node Failures, Link Failures, Middleware Services and also there is a lack of Publicly available datasets for these failures. Majority of researchers have used ARIMA & RNN so to improve the performance of the prediction model we can do some experiments with Generative Adversarial Networks (GAN), Graphical Neural Network (GNN). Also, in our literature survey we found that majority of the publicly available data does not contain time stamp. So to make the future predictions we will need of Time Series data.