...
| Name | Comments on Applicability | Reference |
|---|---|---|
| Hierarchical Clustering |
| |
| k-means |
| |
| Gaussian Mixture Models |
|
...
| Name | Comments on Applicability | Reference |
|---|---|---|
Q Learning | ||
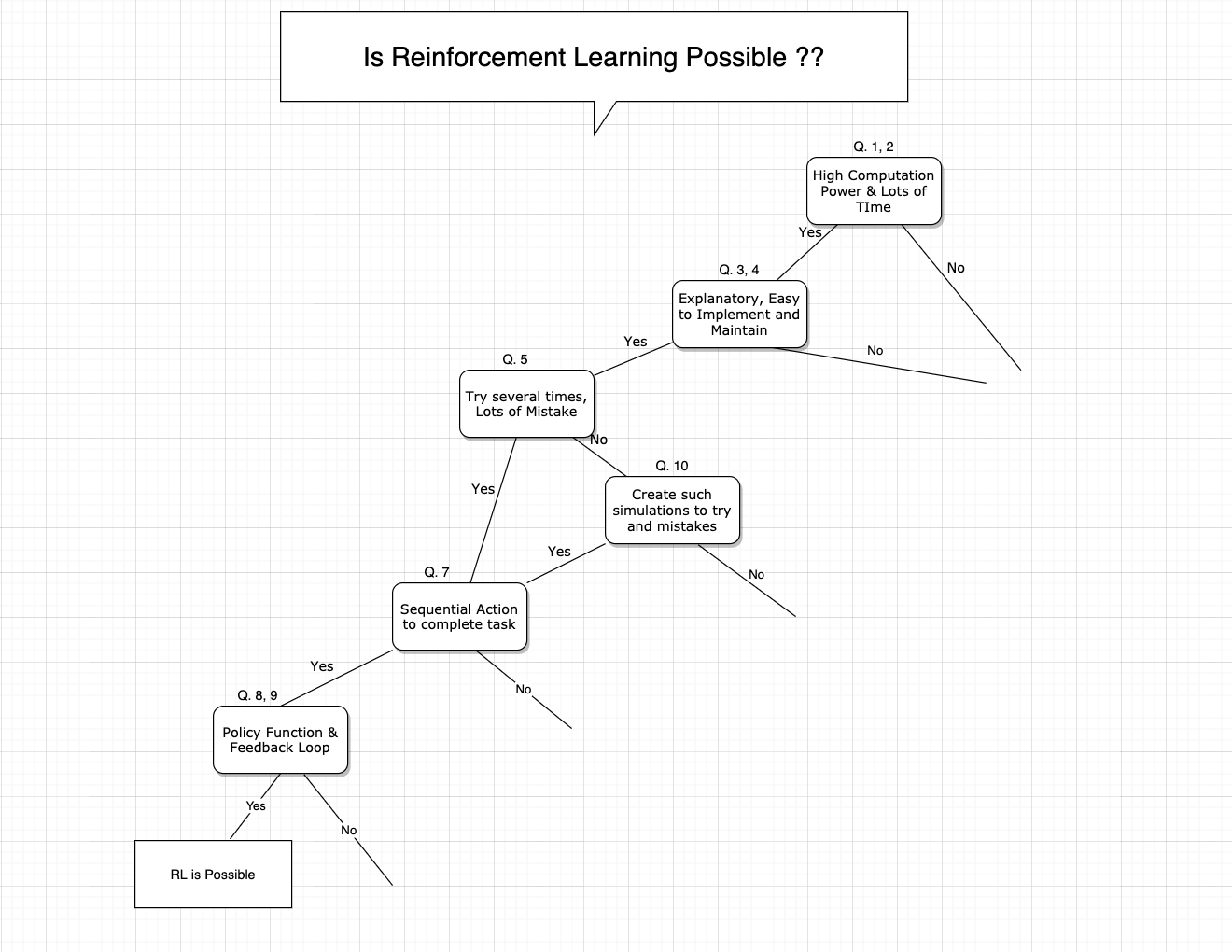
Is RL Possible?
- Do you have very high computation power?
- Do you have lots of time to train an agent?
- Do you need your model to be self-explanatory, humans can understand the reasoning behind the predictions and decisions made by the model?
- Do you need your model to be easy to implement and maintain?
- Is it possible to try the problem several times and afford to make many mistakes?
- In your situation, do active and online learning of algorithms is possible i.e while learning by actions, explore new data space and then learn from such conditions and data?
- In your situation, Can the algorithm take sequential action and complete the task?
- Is it possible to define policy function, actions that the agent takes as a function of the agent's state and the environment.?
- Is it possible to define a function to receive feedback from actions, such that feedback helps to learn and take new action?
- Can you simulate an environment for the task so that algorithm can try lots of times and can make mistakes to learn?