Delivery
- Code
- Documentation
- Output
Code
- Either .ipynb or .py
- requirements.txt - List of dependent libraries
- References, if any code is reused
Documentation
- Document (.md or .rst) how to
- Provide input
- Run
- Collect Output.
- Maximum of 5-Min video of running the code and generating the output – with other description
- Use zoom with screen-share and record to cloud to create this video and send the link.
Output
- Create separate folders for each node.
- Minimum: 1-Node
- In each node-folder
- Create folders for each metrics and place generated files in the these 4 folders.
- CPU (At least 1 of the below three)
- percent-user
- percent-system
- percent-idle
- Memory (At least 1 of the below two)
- used
- free
- Interface (At least 1 of the below two)
- Packets/Octets
- Dropped/Errors
- Load
- load*
- CPU (At least 1 of the below three)
- Create folders for each metrics and place generated files in the these 4 folders.
- Each files should have at least 7000 Entries.
- * Only load file will have more than 2 columns.
- Zip the main folder
- Name it with your team name.
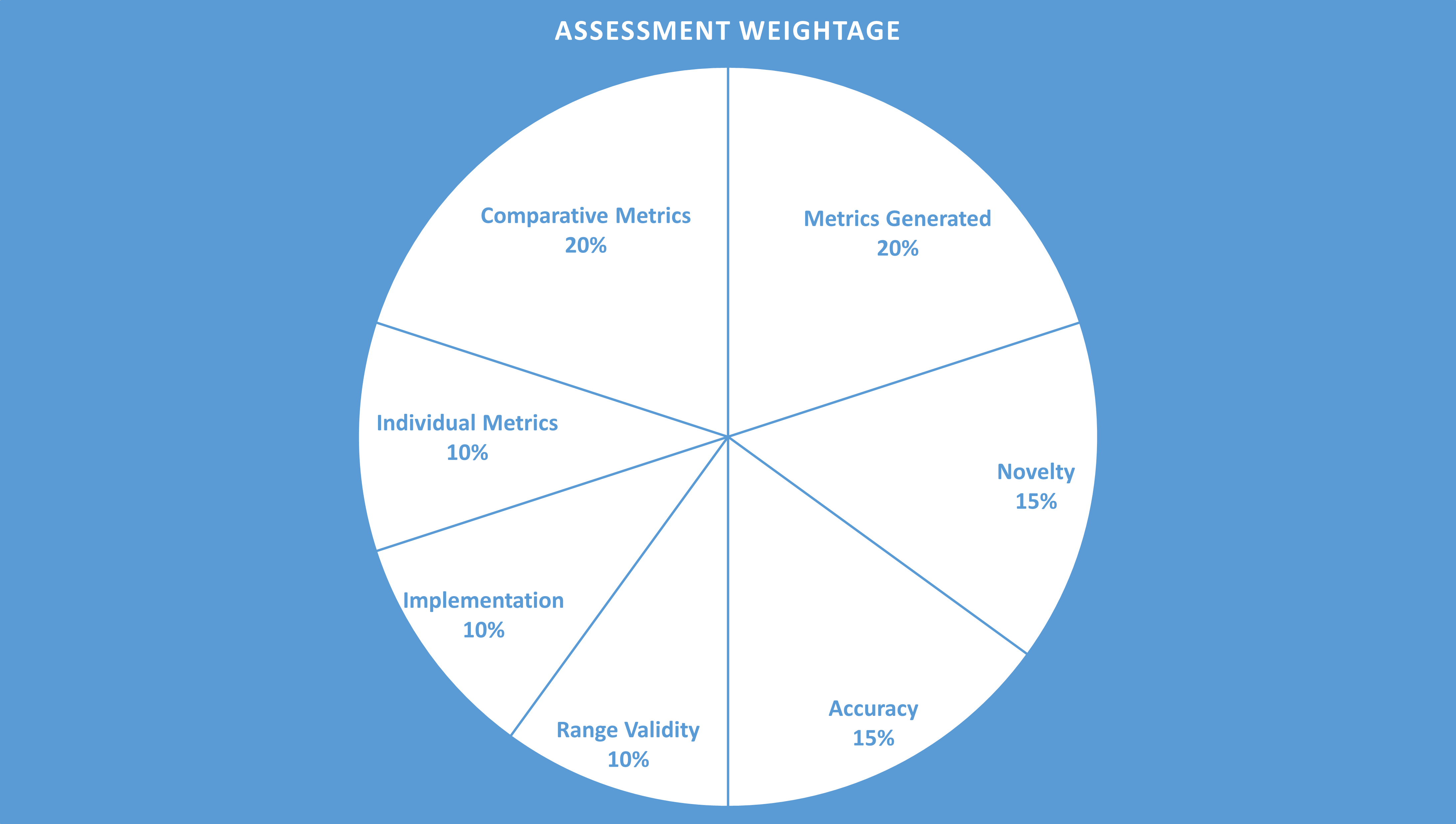
Assessment
Categories:
- Metrics Generated
- CPU, Memory, Network and Load.
- Novelty
- Neural Network
- Discriminator
- Accuracy
- Range Validity
- Max and Mins
- Variations
- Trend
- Implementation
- Code Quality
- Code Re-Use
- Individual Metrics
- Distribution
- Autocorrelation
- ARIMA
- Comparative Metrics
- DTW
- Wasserstein Distance
- RMSE
- Maximum Mean Discrepancy
- Mutual Information