...
"The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance. Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster" 2.
"Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines. If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances. If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes" 2.
...
- Guaranties ordering within the partition.
- Stores all the records as a commit log (for configured interval time, etc.).
- Support partition replication (fault tolerance).
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent.
- A consumer instance sees records in the order they are stored in the log.
- A consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
- Balance messages between consumers in the group.
- There is NO message prioritization support.
Consumer groups

Kafka - collectd
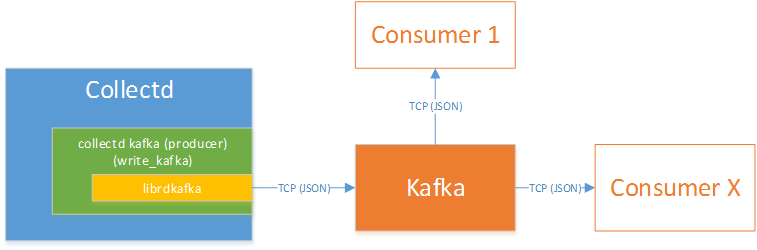
Kafka - collectd
Collectd write_kafka plugin will send collectd metrics and values to a Kafka Broker.
The VES application uses Kafka Consumer to receive metrics from the Kafka Broker.
The new VES application is simply a consumer of the collectd topic.
Collectd VES application with the new schema mapping:
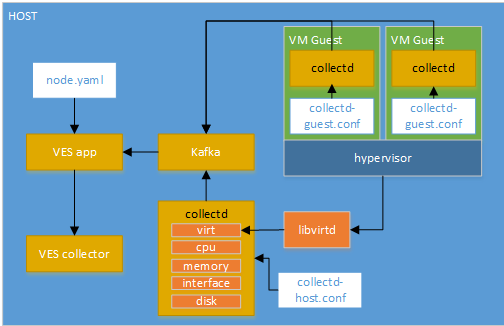
Hardcoding of VES Schema fields has been removed from the implementation of the Collectd VES application. Instead you now provide a YAML file which describes how to map collectd fields/value lists to VES fields. The diagram above shows the usage example for the node.yaml configuration.
Producer throughput:
50 million small (100 byte) records as quickly as possible.
...
Test Case | Measurement |
Single Consumer | 940,521 records/sec (89.7 MB/sec) |
3x Consumers | 2,615,968 records/sec (249.5 MB/sec) |
End-to-end Latency | ~2 ms (median) |
Collectd kafka notification support
TODO
References:
0 https://www.cloudera.com/documentation/kafka/1-2-x/topics/kafka.html
...
2 Documentation (http://kafka.apache.org/documentation.html)
Benchmarking Apache Kafka (https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines)
Robust high performance C/C++ library with full protocol support (https://github.com/edenhill/librdkafka)